논문은 23년 11월에 학회지에 발표된 내용을 정리한 것으로, 빠르게 진화하는 기술을 고려하면 조금 진부할 수 있지만, 국내에서 한국어기반으로 제작한 업체들의 '접근법'을 파악할 수 있습니다. 더불어 국내업체들도 국외업체들을 참조할 수 밖에 없으니 자연스럽게 국제 추세 또는 기반기술에 대한 이해에 도움이 될 것입니다. AI에 대한 중상급 이상의 독자에게 도움을 줄 수 있는 형태로 개조식으로 정리하였습니다. 도움이 되길 바랍니다.^^
LLM 용어
우선 과거에 초거대, 인공모델 등 다소 과장하여 표현된 것은 원래대로 제대로 돌아온 것 같습니다.
단순하게 '거대언어모델'로 학회에서 불려지고 있습니다. 즉, 언어모델(Language Model)이죠.
Large는 한국어로 어떻게 호칭할지 아직(2024.04.09)도 정해지지 않은 것 같습니다.
Large = "대규모", "거대", "초거대", "초대규모",
LLM 태생
- "Transformer 모델의 아키텍처에 파라미터 수를 늘려보니( Layer 또는 Node ) NLP의 여러 기능을 하더라."가 태생인가?
- 이것을 '창발 능력'(Emergent Ability)'이라고 부르는가? (역으로, 대용량의 지식과 많은 수의 파라미터를 요구)
- Zero-Shot(In-Context Learning) 능력. ( 학습하지 않는 새로운 작업을 수행하는 능력, 사전학습과정에서 내재적으로 다중 태스크 학습을 수행하고, 이를 통해 새로운 작업을 수행하는 능력을 습득(거저 주었다?)할 수 있음을 시사)
- Few-Shot Learing 능력.
- 즉, 몇 장의 사진(shot)만 보고 전체 줄거리를 쫙 읊을 수 있다?
Transformer 모델 기반
- 인코더와 디코더로 구성
- 인코더는 주어진 텍스트를 이해하는 역할 ( 글자를 벡터화, Embedding Words , Word Vector)
- 디코더는 이해한 텍스트를 기반으로 언어를 생성해 내는 역할.( 번역문(생성) )
- 인코더만 사용, Google의 BERT( Bidirectional Encoder Representation from Transformers) :: 임의의 토큰을 마스킹하고 마스킹된 토큰이 무엇인지 예측하는 MLM(Masked Language Modeling) 방식으로 학습
- 디코더만를 기반, OpenAI의 GPT( Generative Pretrained Transformer)::이전텍스트를 기반으로 다음에 나올 토큰이 무엇인지 예측(Prediction)하는 NTP(Next Token Prediction) 방식으로 학습, 레이블이 없는 말뭉치.
- 인코더-디코더 사용, Googlem의 다중언어(multilingual) T5 모델, span corruption objectve, 문자 외 음성데이터 등 다른 형태의 입력도 처리, VIT모델(이미지분야), 전통적인 CNN구조를 대체, LG AI: EXAONE모델
- Bert, RoBERTa, XLM, ALBERT, ELECTRA
- TS, BART, B2m-100, BigBird
- GPT-x, InstructGPT, charGPT
LLM을 다소 낮은 사양의 GPU 서버 3-4장으로, 단일 서버에서 운영할 수 있는가? ( Low Resources )
- 양자화(Quantization) 또는 숫자 표현(Representation)의 배정도(Precision)를 조절한다.
- 훈련단계에서도 가능하다는 내용이 있는 것 같음.
Pre-Training ( Full-Training , All-Data) 방법
- Foundation Model을 만듦.
- T5 : 웹페이지
- GTP-3 : 웹페이지, 책, 뉴스
- OpenAI
- Generative(다음언어를 예측) + Pre-Trained + Transformer
- 자동 회귀적 ( auto-regressive) 생성 구조
- 175B 파라미터 ( 1조 7천억 개)
- 모델 입력에 few-shot 예시를 주는 in-context learning을 통해 다양한 NLP 태스크에서 미세조정 없이도 좋은 성능
- GPT-1 : 512 tokens, 12 Blocks, Books, 5GB data, 117M params, 2018
- GPT-2: 1024 tokens, 48 Blocks, WebText, 40GB data, 1.5B params, 2019
- GPT-3 : 2048 tokens, 96 Blocks, WebText/Books, 600GB data, 175B params, 2020, ~ 1,024 A100s for 34 days
- GPT-3.5: CharGPT, GPT-3 + supervised + Reinforcement, 175B params
- GPT-4: ~25,000 A100s for ~90 days
- LLaMa
- Meta AI
- 7B ~ 65B
- 학습데이터 : English CommonCrawl, C4, GitHub.
- SentencePiece : 숫자는 한 자리씩 분리
- Transformer 기반
- RMSNorm 정규화, SwiGLU activatio function, rotary postional embedding(RoPE) 등의 변형
- LLaMa2는 LLaMa에 grouped query attention(GQA) 모델 구조를 추가하고 대화에 최적화되도록 학습
- LLaMa2
- Meta with Microsoft
- 7B, 13B, 32B, 65.2B
- LLaMa-1 65B : 웹페이지(87%), 대화, 책 및 뉴스, 학술 데이터, 코드 데이터
- BLOOM : 다국어 특화, 번역/요약/QA
- decoder only 구조, 공개(public) 언어모델
- ROOTS 코퍼스( 46개의 자연언어, 13개의 프로그램언어, 필터링된 데이터, 비식별화된 데이터)
- Transformer 구조
- ALiBi 포지션 임베딩, Layer Normalization
- 토큰 : 250k의 vocab크기
- Byte-Levle BPE
- 176G, 560M, 1.1B, 1.7B, 3B, 7.1B 파라미터
- RedPajama
- Together AI
- 파운데이션 모델과 학습에 사용된 데이터를 완전히 공개(Public Open)
- 데이터 : LLaMa에서의 데이터 종류와 정제 방법을 따르는 1.2T의 토큰 데이터
- 파운데이션 모델 : Eleuther AI의 Pythina-7B를 사용하여 학습
- Galactica : 과학 도메인
- AlpahCode : 코드 생성
- "다양한 코퍼스의 최적 혼합 비율과 필요한 데이터 양" :: 필자의 한문고전번역::한국고전번역원 사업에서 자주 질문 당했던 사항...
- 학습과정 : missing token prediction 목적함수를 최적화하는 과정
- Genimi ( Dec/2023)
- Google DeepMind
- 1~2T parameters
- Nano-1 1.8B
- Nano-2 3.25B
- Pro ( 6/Dec/2023 )
- Ultra ( 2024 )
- Dataset Size(tokens) : 20T-40T for Ultra
- TPUv4 and TPUv5 for ~120 days
Data 정제
- 학습에 적합한 형태로 데이터를 변환하고 정제하는 과정 필요, 데이터의 품질 확보
- 필터링 : 규칙기반, 모델기반
- 중복제거
- 비식별화
Data Source, 훈련용 데이터
- CommonCrawl : 비영리 단체, 2008년부터, C4/RefinedWeb/Redpajama
- Wikipedia : 온라인 백과사전 데이터
- Code : 프로그램 코드와 그 질의응답 데이터, TheStack 데이터, StackExchange 데이터
Fine-Training ( Specific Domain or Task ) 방법
Instruction Tuning(인스트력션 튜닝) :: 지시어 튜닝
- LLM을 개선할 수 있는 기회를 제공
- 제로샷(zero-shot) 학습 능력을 향상 시키는 전략
- (파운데이션)모델이 지시어를 따를 수(instruction-following) 있도록 '지시어(instuction)'와 '출력(output)'을 사용하여 LLM을 추가로 학습시키는 것을 의미함
- 지시, 입력, 출력 형태의 데이터로 구성( 기존에 존재하는 NLP분야의 특정한 태스크, 즉 번역, 요약, QA 관련 데이터를 형식화, 모델로부터 합성된 데이터..)
- 구축 방법 1 : 어노테이션 데이터셋을 활용, 기존 Text-Lable 쌍을 (지시어, 출력) 쌍으로 변환, FLAN 데이터셋, P3 데이터셋
- 구축 방법 2 : 주어진 지시어에 대한 출력을 GTP-3.5-Turbo 또는 GPT-4를 사용, InstructionWild 데이터셋, Selt-Instuct 데이터셋
- 멀티턴 대화형 지시어 : LLL이 서로 다른 역할( 사용자 및 AI 어시스턴트 )을 스스로 수행
- 튜닝 방법 : supervised fine-tuning(SFT) 방식
- 본 적 없는 태스크에 대한 일반화 능력
- 미세 조정하는 추가적인 과정을 의미
- 기존의 지도학습 패러다임과 유사
- 비교적 적은 수의 예제만으로 뛰어난 성능 및 새로운 태스크에 일반화가 가능(multi-task prompted training)
- Instruction == Template == Prompt
- 지시사항의 다양성과 품질이 예제의 개수보다 더 중요
- General-purpose task solver > Domain-specialized task solver
- FLAN, 12개의 작업클러스터 예시
- 어려운 점 : 풍부한 데이터셋이 필요, 그에 따른 다양한 인스트럭션이 필요, cross-lingual instruction tuning (즉 번역),
- 예시 ( squad_kor_v1 from HuggingFace )
- Alpaca : GPT-3.5에서 생성된 52만 개의 지시어 데이터셋( instruction-following dataset)을 활용
- Vicuna : ChatGPT와 사용자 사이에 공유된 7만 개의 대화 세트로 구성된 약 700만 개의 지시어 데이터셋을 활용
- 주로 영어와 중국어...
지시어 데이터셋( Instruction Dataset )
- Natural Instruction : 61개의 NLP Task, 193,000개, 인간 주석자가 직접 만듦. 영어기반. { 지시어, 인스턴스 : { 입력, 출력 }}
- P3 (Public Pool of Prompt): 170개 영어 NLP 데이터셋, 2,052개의 영어 프롬프트, { 입력, 답변선택지, 타겟 }
- FLAB : 62개의 널리 사용되는 NLP 벤치마크를 입력-출력 쌍으로 변환, 영어, {입력, 타겟}
- Self-Instruct : InstructGPT를 사용하여 구축된 5만 개 지시어 + 252개의 평가 지시서, 영어,
- Alpaca : Self-Instruct 데이터셋의 일부를 시드 데이터로 사용하여 GPT-3.5-Turbo를 사용하여 답변을 생성 ( Alpaca모델은 구축한 지시어 데이터셋에 LLaM-7B를 미세조정(Fine-Tuning)하여 학습된 언어모델 )
- Vicuna: ShareGPT 홈페이지에서 사용자가 공유한 ChatGPT대화를 수집 후, 70K의 대화 기록을 학습데이터로 사용( Vicuna모델은 구축한 데이털에서 LLaMa-13B를 미세조정(Fine-Tuning)하여 훈련된 언어모델임)
- GPT-4-LLM: Alpace의 지시어를 GPT-4를 통해 출력하여 수집, 52만 개의 지시어와 출력 쌍으로 구성
- Dolly: Databricks에서 제작, 15만 개의 데이터( 행동 커테고리 :: 브레인스토밍, 분류, 폐쇄형 QA, 생성, 정보추출, 요약, 개방형 QA 등)
- ShareGPT: 90만 개의 데이터, ChatGPT와 사용자 간의 대화를 수집, 필터링 도구( langid ), 10자 미만을 필터링
인간의 피드백( Human Alignment )
- 인간의 가치와 기준에 부합하도록 조정하는 접근법
- 사용자 만족도 정렬(Human Preference Alignment) < ChatGPT의 상업적인 성공요소, Bradley-Terry모델(사용자 만족도 우선순위를 표현), Chatbot Arena 방식, LLaMa-2의 경우 약 142만 건의 사용자 선호도 데이터
- LLM의 의도치 않은 행동을 방지하기 위한 방법론
- 고품질의 human feedback 수집이 필수적이라, 상대적으로 많은 비용이 소모
- Reinforcement Learning from Human Feedback(RLHF) :: 강화학습법 중의 하나, InstructionGPT, ChatGPT에 적용됨. SFT, RM(Reward Model), PPO(Proximal Policy Optiomization) Algirithm
- 부작용 :: 인간의 주관적인 alignment criteria의 특성에 의한, 기본능력을 감소, alignment tax
- PPO( Proximal Policy Optimization) : 강화학습 기법, 사용자 피드백 주입, OpenAI의 InstructGPT모델, Mata의 LLaMa2-chat모델, Anthropic의 Claude2 모델, Policy모델, KL-divergence로 제약
Resource-Efficient Fine-Tuning ( or Parameter Efficient Tuning)
- 큰 규모의 모델 파라미터를 갖는 LLM의 효율적인 학습을 위한 방법론(들)
- Parameter-Efficient Fine-Tuning(PEFT) :: 원래의 언어모델의 파라미터는 고정 후, 특정 계층(Layer)만
- Adaptor Tuning
- Prefix Tuning
- Prompt Tuning
- Low-Rank Adaptation(LoRA) : low-rank approximation, 메모리 및 스토리지 비용 절감, 모델의 일부분을 학습, GTP-3 175B의 경우, 파라미터 수를 10,000배, GPU 메모리 사용량 3배 줄임.
- LLaMa-Adapter : 7B의 파라미터 수 > 1.2M 개만의 학습 파라미터로..... 52K 개의 지시어 사용, 지시어를 따르는 모델, Transformer 레이어 상당에서 학습 가능한 Adaptation 프롬프트를 단어 토큰 앞에 붙인다. zero gating, zero-initialized attention.... fully-tunned Alpaca보다 품질이 좋은 답변 생성
- Flash Attention : 모델 구조를 효율적으로 변경, 읽기 및 쓰기에 대한 정로를 GPU메모리 단계에서 보다 효율적으로 고려. 기존 Transformer의 attention에 비해 GPT-2 모델 기준 약 3배 빠른 속도로 처리
Memory-Efficient Fine-Tuning
- 양자화(quantization) 등의 모델 압축(compression)
** 참조 :: FlexGen :: 1개의 GPU에 큰 모델을 탑재
활용/사용
ICL(In-Context Learning) ::인컨텍스트 러닝
- 프롬프팅 방법 중의 하나
- 태스크 설명문과 태스크 질문 및 정답 쌍으로 구성된 예시들(examples), 질문으로 이루어진 프롬프트(prompt)를 자연어 형태로 입력하면, 주어진 입력 정보를 참고하여 모델이 답변을 생성하는 방법
- 몇 가지 예시만으로 언어모델이 태스크를 학습
- Training-free learning(추가학습 없이 해결)
- GPT-3는 여러 태스크에서 인컨텍스트 러닝으로 기존 미세조정된 모델들을 뛰어넘는 성능을 달성
- Scalable
- 어떤 원리로 작동하는 것일까? 규명을 위한 여러 가지 가설...을 기반으로 연구된 자료 존재
CoT(Chain-of-Thought)
- 입력과 출력 사이의 중간 추론단계(intermediate reasoning steps)를 시연형태로 추가
재귀적 프롬프팅
- compositional generalization 능력
특수활용
- LaMDA : 대화 애플리케이션, 검색모듈, 계산기 및 번역기, 외부도구 호출 기능
- WebGPT : 웹 브라우저와 상호작용
- PAL : Python 인터프리터를 통한 복잡한 기호추론 기능 제공
- 다양한 종류의 API 호출 기능( 계산기, 달력, 검색, QA, 번역)
- LangChain 프로젝트
- ChatGPT Plugin 프로젝트
- 국내, CLOVA X, 네이버 내부 및 제휴사 API만 연동..
Augmented LLM
- Augmented Data와는 조금 다르다?
- LLM을 추론(reasoning) 및 도구사용(use tools) 관점에서 강화한 모델을 칭함
- Retrieval Augmented Generation(RAG) : Information Retrieval, retriever/generator , LG AI센터, Naver, KT
- 환각 문제를 해결하고자...
- 단순 텍스트 형성이 아닌 정보검색(IR : Information Retrieval) 차원으로 확장
- 검색 문서 기반으로 응답을 생성
- 사용된 문서를 참고 문헌으로 표현하는 기술
- 신뢰성 향상, 출처 인용
- New Bing, Perplexity.ai, Google 검색
Evaluation Data, 평가 데이터
- 언어생성 능력 : LAMBADA(문장을 완성), XSum(문서를 요약)
- 지식활용능력 : Closed-book QA 태스크(사전에 학습한 지식만을 이용해 답변):: Natural Questions, ARC, Truthful, Open-book QA 테스트(외부 지식을 활용해 답변) ::Wikipedia
- 추론 능력 : 일반상식 추론:: PiQA, HellaSwag, WinoGrande, 수학적 논리테스트:: GSM8K
모델경량화
- 양자화( quantization ) :: numerical precision, integer quantization.... 실제 추론 시에는 integer값, scale값, zero값을 저장해 놓고 이를 원해 실숫값으로 복원해서 사용
- 지식증류( knowledge distillation ) :: teacher-model, student-model
- 가지치기( pruning )
OpenSource LLM
Falcon, Llama, Claude, QWen
한국어 OpenSource LLM
- 소스 코드 및 recipe가 공개된 것인지? 훈련된 한국어 전용 모델이 공개된 것인지?
- K(G)OAT
- IA3 방법 ( > LoRA 방식보다 더 효율적인 방법론 )
- KoAlpaca 모델을 미세조정(Fine-Tunning)
- 학습에 사용된 데이터셋은 KoAlpaca v1.1을 활용해 프롬프트 구성을 수정하여 사용
- A5000 GPU 2장, 4 epoch... > 226분 ( 4시간 미만 )
- KoAlpaca
- 데이터셋 : Alpaca 데이터셋의 지시어를 DeepL로 번역 후, GTP-3.5-turbo를 사용해 출력을 생성(한국어)
- 미세조정(Fine-Tuning) : LLaMa와 Ployglot-ko모델을 기반으로 학습
- KoVicuna
- 데이터셋 : ShareGPT( ChatGPT와 사용자 간의 대화 데이터) 데이터를 한국어로 번역(한국어)
- 미세조정(Fine-Tuning): LLaMa모델 기반으로 학습(training)
- Eleuther의 Polyglot-Ko ( 1.3B, 3.8B and 5.8B, 12.8B Korean autoregressive language models )
- 블로그, 뉴스, 특허, 위키피디아
- 863GB의 텍스트
- GTP-NeoX를 기초모델로
- Tokenizer : 30,003개의 vocab크기
- 형태소 기반의 Byte level BPE( Byte-Pair Encoding)
- 형태소 분석 : MeCab
- 1.3B, 3.8B, 5.8B, 12.8B
- KORani
- ShareGPT 영어버전과 한국어 번역 버전
- human과 gpt에 해당하는 대화의 첫 번째 부분과 두 번째 부부만 추출하여 학습
- LLaMa와 Ployglot-Ko모델을 기반
- A100 40GB GPU 8장
- KULLM
- 고려대학교 NLP&AI 연구실과 HIAI연구소
- Ployglot-Ko모델을 기반 LoRA를 사용하여 학습 ( KU LLM모델 구축)
- A100 GPU x 4장, 5 epoch
- PEFT 라이브러리 사용( LoRa)
- GPT4-LLM, Dolly, ShareGPT를 DeepL로 번역 ( 한국어 )
- 150만 개의 한국어 데이터셋
- NA-LLM
- LLaMA-2-Ko
- LLaMA2를 기반으로 최적화된 Transformer 구조 기반의 자동회구 언어모델
- 확장된 Vocab
- 한국어 말뭉치를 추가 사전에 포함
- 기존 32,000 크기의 LLaMa2의 vocab > 한국어 vocab을 추가 > 46,336 크기의 vocab으로 확장
- komt
- LLaMA2 모델을 기반
- 번역된 데이터를 사용하지 않음.
- KorQuad, AIHub, KISTI AI데이터셋, 순수 한국어 데이터셋을 활용
- 각 작업(Task)에 맞는 다중 작업 데이터셋을 구축
- 구축된 데이터를 활용하여 학습 후, 모델을 만듦
- Ko-Platypus
- KOpen-Platypus 데이터셋을 활용 ( Open-Platypus를 DeepL을 사용해 번역, 25,000개의 데이터를 수작업으로 체크)
- LLaMA-2-Ko를 미세조정(Fine-Tuning)한 모델
LLM 자체 학습 ( 자체 엔진과 자체 학습은 구분하여야 함. ) :: 국내
- Naver Clova의 HyperClova
- Kakao Brain의 KoGPT
- SKT의 에이닷
- 전화통화 요약
- 프로필 이미지 생성
- KT Enterprise의 믿음
- 210B, 한/영 다중언어, 초경량모델, 멀티태스크,
- 통합 SW (Full Stack) :: 다양한 GPU클라우드 인프라, 개발 및 운영 플랫폼, LLM 파운데이션 모델, 도메인 적응 학습을 위한 개발 도구
- LG AI Research의 Exaone, 이중언어 모델(한국어/영어), 전문가용 대화형
- NCsoft의 VARCO
- VARCO 기반 교육전용 언어모델 구축 예정(23.10.16)
- Saltlux의 Luxia
- 코난테크놀로지의 Konan
- 기업내부에 설치-운영, 데이터 유출 우려 원천방지
- 벡터 검색을 통한 답변의 증강
- 근거 제시가 가능
- 중형 LLM 개발:13B,41B, ( LLaMa2:7~70B, Dolly 2.0:12B, Vicuna 13B, Falcon 40B) :: 수십 Billion 내외 )
- 토큰은 5천억, 7천억 개
- 파라미터 크기는 크지 않게, 토큰은 많이 학습하는 접근법
- 인피니밴드로 묶인 H100 x 8, 서버 8대, (H100 memory: 80GB or 188GB )
- 23일 소요
- 인피니밴드 필요성 : 20Gbps네트워크에서 1 echo 수행 시, 모델파라미터 전송에 34초 소요. 를 인피니밴드에서 1초 소요
- 학습 데이터 : AIHUB, 위키피디아( 이상 공개 데이터), 뉴스, GitHub (이상 구매 데이터), Books3, Gutenberg 등의 영문데이터
- 한국어 토큰(Token) 수 : 3,318억 개 ( ChatGPT: 5.9억 개, LLaMA-2: 12억 개 )
- 여러 태스크로 훈련하였을 때가 단일 태스크로 훈련하였을 때보다 약 10%p 성능이 더 나았다.
- 저사양 서버 환경에서 운영 가능 :: RTX 3090 x 2장 ... 3D병렬화, bfloat16, Zero Redundancy Optimizer, FlashAttenstion
- 고객사 데이터, 전체 미세조정 훈련 시, H100-80GB * 8 장 ( 6초/1echo ), RTX6000-48GB * 8장( 30초/1echo )
- PEFT 기법 중 QLoRA : GPU메모리 절감
- 검색 증강 생성 (RAG), Re2G, 벡터기반 시맨틱 검색과 결합한 RAG,
- 문장 생성, 질문-답변, 요약, 고쳐쓰기(/교정), 분류, 번역
- (BM) 업무문서/보고서 초안 생성, 계약서 검토, 고객 맞춤 상담(AICC, 고객 질의에 대한 고객 개인정보, 보험약관, 고객 개인정보와 금융상담 등에 기반한 답변생성), 고객 상함 후처리 자동화( 자동요약)
- 업스테이지의 Solar-0-70b모델, 한국어/영어, LLama2를 Fine-Tunning
한국어 LLM 리더보드
- Open Ko-LLM Leaderboard
신경망 모델 & LLM 배포 및 운용 : 모델 호환성, 상용서비스
ONNX Runtime : Open Neural Network Exchange, Miscosoft and FaceBook(Meta), run on device or on browser, also support custom model,
OpenNMT 사이트에서는 다양한 Transformer모델 기반의 모델을 converting 및 loading하는 샘플 코드가 있음. 기계번역모델 뿐만 아니라, 음성인식 등 multimodal LM을 사용할 수 있음. 아마도 최초는 Huggingface에 있는 듯합니다.
LangChain a framework for developing applications powered by language models.
LangSmith
Fabric build AI agents with its drag-and-drop interface
ETL tools Extranction, Transform and Load process. such as
- Talend Open Studio(TOS)
- Integrate.io
- Hevo Data
- Fivetran
- Stitch
- AWS Glue
- Azure Data Factory
- IBM DataStage
- Informatica PowerCenter
- Apache Airflow
고려 대학교 NLP&AI 연구실의 실험환경
- 기본 모델 : Eleuther에서 공개한 Ployglot-Ko 5.8B, 12.8B 한국어 LLM모델 ( 868GB의 한국어 데이터, 블로그, 모두의 말뭉치, 위키 등 다양한 도메인)
- 지시어 데이터셋 : GTP-4-LLM, Dolly, ShareGTP를 한국어로 번역
- 학습 기법 : SFT(Supervised Fine-Tuning)
- 파라미터 효율적인(parameter-efficient) 학습 : LoRA를 query key value attention 레이어에 적용.
- 외부 요소 : A100 GPU( 80GB VRAM) x 4장, 5 epoch...
- LoRA 학습 : PEFT 라이브러리 사용
- 학습 과정의 메모리 효율성 최적화 : BitsandBytes를 활용
- Criterion : AdamW optimizer
- Learning Rate : 최대치를 3e-4
- Warm-up 코사인 스케줄러 : 5%
- Gradient explosion 완화 : grandient clipping 적용
- Batch 사이즈 : 256 ( 128, 256, 512 중에서 )
- LoRA Rank : 16
- LoRA Alpha : 32
- Decoder : temperature=0.1, top k=40, p=0.75, do sample=False, num beams=4, repetition penalty=1.4 max new tokens=400
사업적 측면에서 Large AI
- 요구사항
- 맞춤형
- 우리회사의 데이터를 잘 이해하는 모델
- 우리가 필요한 몇 가지 기능이 우선 잘되었으면...
- 오랜 구축시간이 필요하지 않고 빠르게 구축되었으면...
- 우리 데이터가 외부에 노출되지 않도록 내부에서 구축...
- 효율성
- 빠른 속도의 응답이 필요
- 높은 성능이 필요
- 몇 가지 기능만을 적은 비용으로 구축이 가능하였으면...
- 신뢰성
- 우리 데이터에서는 환각현상이 없이 정확한 정답만을 제공하였으면...
- 국민을 대상으로 하는 서비스를 만들 것이므로 비윤리적인 응답은 제공하지 않아야...
- 편리성
- AI를 잘 모르는 우리 직원들도 쉽게 서비스를 개발할 수 있었으면....
- 맞춤형
- Fast Adaptation :: 빠르게 고객 특화 모델을, 성능을 확보하면서 만드는 방법론
- 일반적인 AI의 학습 방법 : 해당 영역의 어휘나 지식을 포함하는 적응학습용 데이터, Full Fine-tuning... 수많은 GPU... 몇 달 이상의 오랜 학습시간..
- 효율적인 학습밥법 : PEFT(Parameter-efficient Fine Tuning)..
- 더 효율적인 방법 : Prompt engineering기법, zero-short/few-shot/instruction/in-context learning/
- 초경량화 기술 :: 추론에 소요되는 비용을 최적화... 운용 비용 절감..
- 경량화 방법 : 지식증류(Knowledge Distillation), 양자화(Quantization), 가지치기(Pruning).... 1/10로 축소 가능..
- 유효성, 신뢰성, 윤리성 :: 정확성 이외에도 갖추어야 할 소양 항목
- 멀티 태스크 학습( 다양한 질문 유형 대응 가능하도록) :: FLAN 데이터셋, Super Natural Instruction.
- 강화학습( 사용자가 좀 더 원하는 형태의 응답으로 ):: CharGPT, Bard, Claude 데이터셋과 같은 실제 대화형... 또는 합성데이터
- FCC(Factual Consistency Checker) 기술 :: 사실적 일관성 여부 검토
- RAG(Retrieval Augmented Generation) 기법 :: 검색 증강형 생성.
- 강화학습을 위한 평가지표, 윤리성 정의 분류 체계
Reference
- 초거대 언어모델 연구 동향, 업스테이지 박찬준 외, 정보과학회지, 2023.11
- 생성형 AI시대 거대언어모델의 기술동향, LG AI연구원, 김소연 외, 정보과학회지, 2023.11
- 코난 LLM : 한국어 대규모 언어모델, 코난테크놀로지, 양승현 외, 정보과학회지, 2023.11.
- 한국어를 위한 지시어 튜닝 조사 연구: 거대 언어모델 학습 및 적용, 고려대학교, 이승준외, 정보과학회지, 2023.11
- Large AI to Everywehre, 초거대 AI 믿:음, KT융합기술원, 장두성 외, 정보과학회지, 2023.11
- LLM 기반의 네이버 검색 서비스 Cue: , Naver 유홍연 외, 정보과학회지, 2023.11
- https://medium.com/
추가작성( 23.12.26)
Tree of GPTs & LLMs

- 나무(Tree) 구조의 뿌리는 Word2Vec와 그 친구들임.
- 메인 가지(Branch)는
- 인코더(Encoder)만 :: BERT가 대표. Cotinuous vector representations, downstream tasks( text classification, sentimental analysis, named entiry recognition), converting raw text into a sequence of tokens and generating contextual embeddings of each tokens, feature extraction. self-attention mechanism, capture long-range dependencies and learn contextual representation. Word-like tokens( e.g. WordPiece, SentencePiece ). NOT traditional word vectores. initial embeddings in GPT are not fixed and can be further refined....
- 1. Tokenization :: Convert input text into a sequence of word-like tokens( words or subword units ) using an appropriate tokenizer
- 2. Embedding :: Map each tokens to its initial embedding using an embedding matrix learned during training
- 3. Postional encodeing :: Add postional encodeings to these embeddings to capture information about their positions within sequences
- 4. Transformer layers :: Process these position-aware embeddings through multiple self-attention and feed-forward layers, refining contextual relationships between tokens at each layer.
- At the output layer, the decoder produces logits for all the possible tokens in its vocabulary.
- 5. Softmax activation :: apply softmax activation on logits to obtrain probability distributions over all potential tokens for predicting the next token in a sequence
- The ‘decoding’ process essentially refers to generating output text based on this estimated probability distribution conditioned on preceding tokens and context information provided as input to the model.
- As a result, GPT generates contextualized representations for each token in the sequence by capturing both local and long-range dependencies across tokens. This approach allows GPT and other Transformer-based LLMs to better understand linguistic patterns and relationships compared to fixed-word vector methods.
- 디코더(Decoder)만 :: GPT, Bard, LaMDA, generate output text based on the givien context( e.g., a prompt ), text generation tasks( story generation, conversation modeling, or completing sentences )
- 인코더-디코더:: T5, BART가 대표, machine translation, summarization and question-answering
- 인코더(Encoder)만 :: BERT가 대표. Cotinuous vector representations, downstream tasks( text classification, sentimental analysis, named entiry recognition), converting raw text into a sequence of tokens and generating contextual embeddings of each tokens, feature extraction. self-attention mechanism, capture long-range dependencies and learn contextual representation. Word-like tokens( e.g. WordPiece, SentencePiece ). NOT traditional word vectores. initial embeddings in GPT are not fixed and can be further refined....
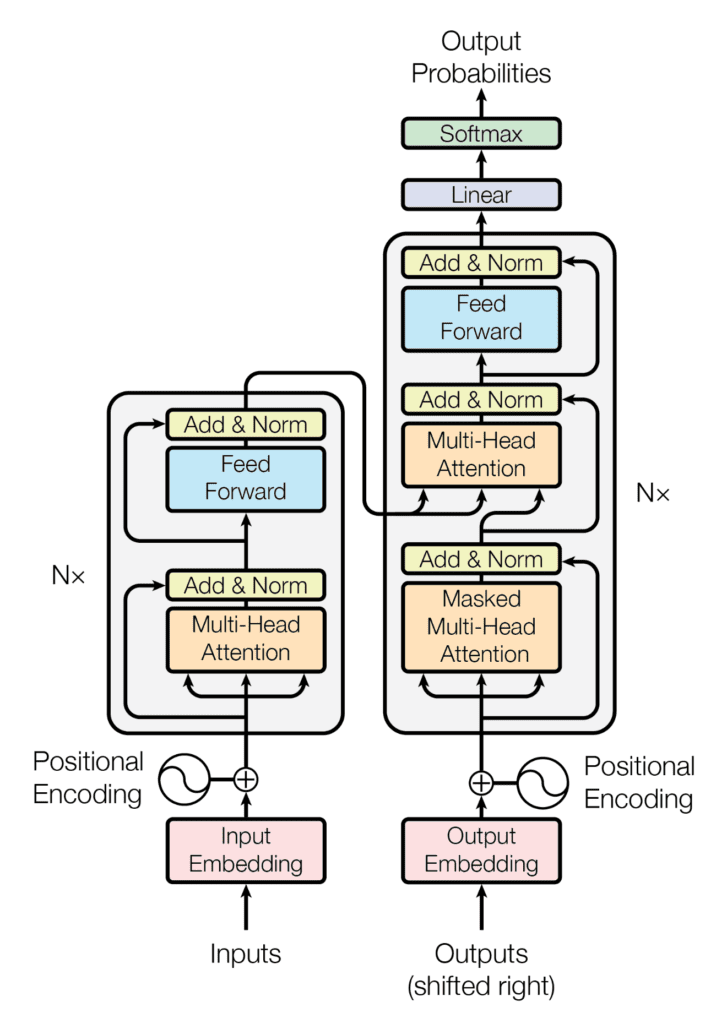
Transformer Architecture
LangChain
- LangChain Libraries :: langchain-core, langchain-community, langchain
- LangChain Templates
- LangServe
- LangSmith

Infra cost
$45.0 per hour for 8 NIVIDIA A100 GPUs ( 640 GB )
$0.6 per hour for one NVIDIA T4 ( 14GB )
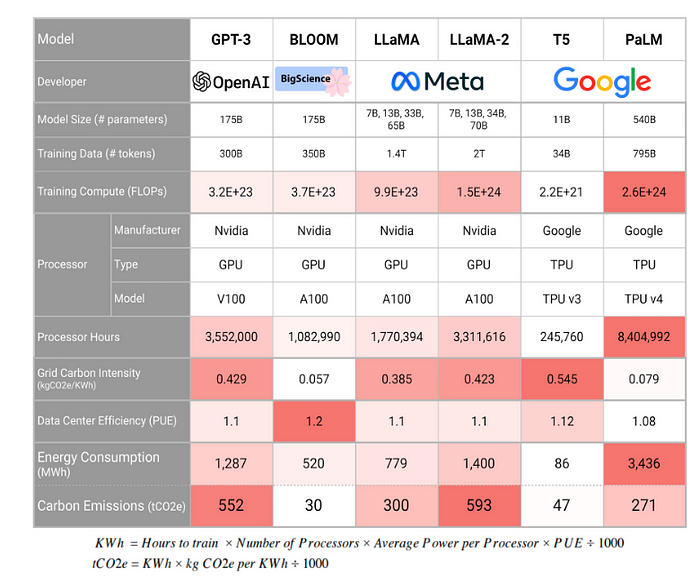
CO2 Emissions:
Fine-Tunning Pricing matrix


'IT' 카테고리의 다른 글
| openCLAW, 서비스 구축 및 연동 (0) | 2026.03.05 |
|---|---|
| MongoDB, 5.0+, CPU가 AVX 미지원시 설치 오류 메시지, VM이슈 (1) | 2024.05.22 |
| [카카오계정 SSO 인증] 앱 관리자 설정 오류 (KOE009) (2) | 2023.12.05 |
| [정의] Crawl Depth (0) | 2023.10.13 |
| [ 도메인 관리 ] wildcard subdomain, 가비아 (0) | 2023.09.08 |