아래 사이트에서 아주 잘 설명되어져 있네요.
시계열 데이터의 대표적 사례는 음성신호 데이터가 될 것입니다.
NLP에서 문장도 순서는 있지만, 물리적 시간 측면에서는 일 순간에 밀어 넣을 수 있죠. 이 점이 다릅니다.
위와 같은 특성 때문에, 딥러닝 알고리즘/아키텍처는 NLP에서 먼저 나오고, 좀 더 시간이 지나야 Speech쪽에서 기술이 도출되는 경향이 있습니다.
아래 URL에서 소개하는 시계열 데이터 분석법의 목록은
1. Machine Learning Approaches
1.1 ARIMA (AutoRegressive Integrated Moving Average)
1.2 SARIMA (Seasonal ARIMA)
1.3 Prophet
1.4 XGBoost
2. Generative AI Approaches
2.1 GANs (Generative Adversarial Networks)
2.2 WaveNet
3. Deep Learning Approaches
3.1 LSTM (Long Short-Term Memory)
3.2 GRU (Gated Recurrent Unit)
3.3 Transformer Models
3.4 Seq2Seq (Sequence to Sequence)
3.5 TCN (Temporal Convolutional Networks)
3.6 DeepAR
각 항목은 아래와 같이.
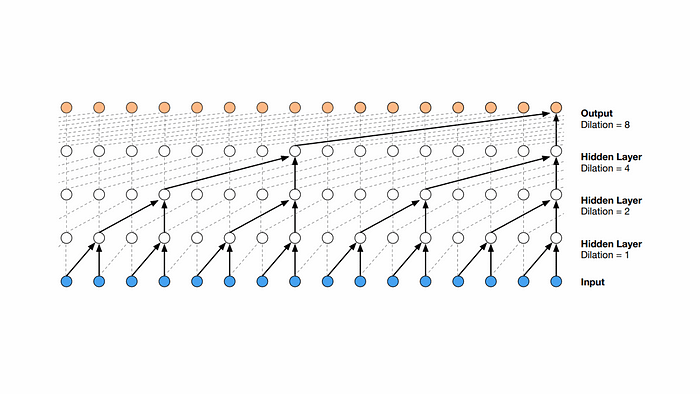
아키텍처/순서도/설명도 등의 이해를 돕기 위한 도해 1개 와

주요 특성을 간략하게 3-5줄로 설명을 하고, 그 뒤에 예제 샘플 코드가 뒤 따르는 형태로 되어 있다.
Predicting Time Series Data with Machine Learning, Generative AI, and Deep Learning
Time series data prediction is a critical aspect of various industries, ranging from finance and healthcare to marketing and logistics. The…
medium.com