참조 논문(2021년 논문) : https://arxiv.org/pdf/2106.15561.pdf
Articulatory Synthesis ::
- simulating the behavior of human articulator such as lips, tongue, glottis and moving vocal tract.
-The speech quality by articulatory synthesis is usually worse.
Formant Synthesis ::
- a set of rules that control a simplified source-filter model.
- mimic the formant structure and other spectral properties of speech
- an additive synthesis module and an acoustic model with varying parameters like fundamental frequency, voicing, and noise levels.
- highly intelligible speech with moderate computation resources
- well-suited for embedded systems
Concatenative Synthesis
- concatenation of pieces of speech that are stored in a database.
- searches speech units to match the given input text, and produces speech waveform by concatenating these units together.
- requires huge recording database in order to cover all possible combinations
- less natural and emotional
Statistical Parametric Synthesis
- first generate the acoustic parameters then recover speech from the generated acoustic parameters
- consists of three components: a text analysis module, a parameter prediction module (acoustic model), and a vocoder analysis/synthesis module (vocoder).
- text analysis module
: text normalization , grapheme-to-phoneme conversion , word segmentation, etc
: phonemes, duration and POS
- a parameter prediction module(Acoustic Model)
: The acoustic models (HMM based)
: the paired linguistic features and parameters (acoustic features)
:: acoustic features :: F0, spectrun, cepstrum..
- vocoder analysis
- 장점
: 1) naturalness, 2) flexibility, 3) low data cost
- 단점
: lower intelligibility, still robotic

cf.) 음성인식과 연결하면, Feature Analysis, Acoustic Model, Search Algorithm.(outputs text )
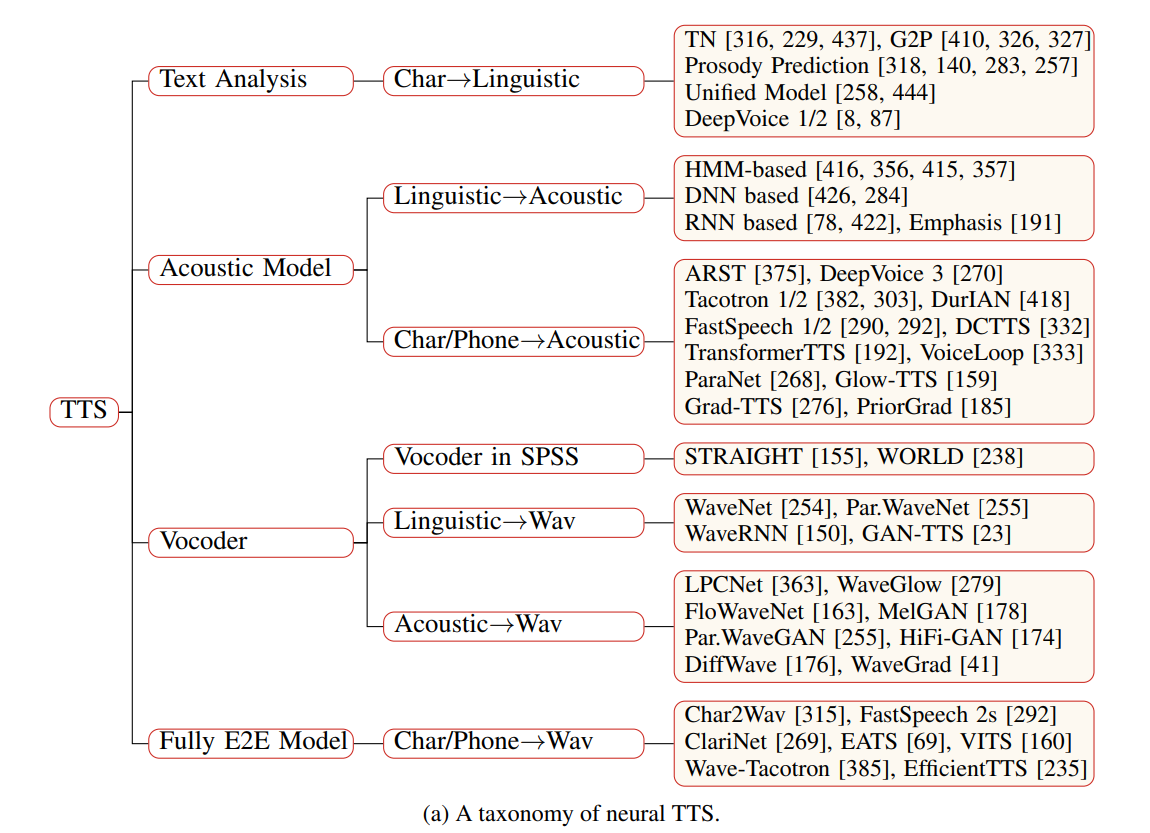
Neural Speech Synthesis
- early neural models :: replace HMM for acoustic modeling. (3 components ) : DeepVoice 1/2
- directly generate waveform from linguistic features(2 components ) : WaveNet
- some end-to-end models: Tacotron 1/2, Deep Voice 3, FastSpeech 1/2
1. simplify text features.
2. directly take characters/phonme sequences as input,
3. simplify acoustic features with mel-spectrograms.
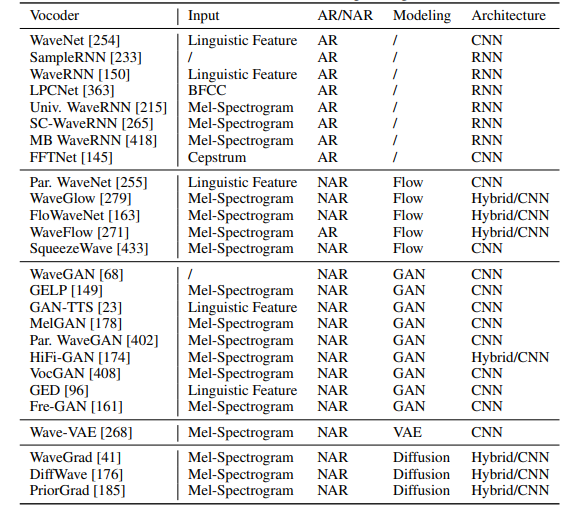
( 그림 1 참조.)
- fully end-to-end ( directly generate waveform form text ) : ClariNet, FastSpeech 2s, EATS
==> high voice quality in terms of both intelligibility and naturalness,
less requirement on human preprocessing and feature development



'IT' 카테고리의 다른 글
| OpenAI가 말하는 챗GPT(ChatGPT) 제약점(limitations)는? (0) | 2023.02.01 |
|---|---|
| nouveau driver Disable 진행 (0) | 2023.01.30 |
| AIX 서버, 클라우드 임대 (0) | 2023.01.30 |
| [벤츠 순정 블랙박스] Starview S, 동영상 PC보기 (0) | 2023.01.30 |
| Apache( apache + php ) 기본 설치 via rpm (0) | 2023.01.25 |